- OpenAI’s GPT-4o: The latest flagship, renowned for its multimodal prowess and sophisticated reasoning.
- Google’s Gemini 2 Flash: A nimble powerhouse balancing speed and intelligence, built for real-world applications.
- Meta’s Llama 3.2 (3B): A smaller but capable iteration of Meta’s hugely popular open-weight model family, pushing the boundaries of open-source AI.
The Gauntlet: Turning Scientific Jargon into Actionable Knowledge Graphs
Imagine you’re reading a research paper abstract. Your expert eye quickly spots key terms: “ImageNet” (a Dataset), “Convolutional Neural Network” or “BERT” (Methods), “Image Classification” or “Named Entity Recognition” (Tasks).- Spotting the Actors (Entity Extraction - NER): This is about identifying these key terms and correctly labelling them – Is this a Method, a Task, or a Dataset?
- Mapping the Connections (Relation Extraction - RE): This is the trickier part. How do these actors relate? Is “BERT” Used-For “Named Entity Recognition”? Is “Method A” being Compared to “Method B”? Is “Method C” Evaluated-On “ImageNet”?
The Proving Ground: Why SciER?
To conduct a fair fight, we needed a high-quality arena. We chose SciER (paper, GitHub), a well-respected benchmark dataset specifically designed for this kind of challenge in the scientific domain. Why SciER?- Gold Standard: It’s meticulously annotated by humans, providing a reliable “ground truth” to measure against.
- Real-World Complexity: It uses actual scientific abstracts, forcing the models to grapple with authentic complexity and jargon.
- Community Trust: It’s an established benchmark used by researchers to evaluate NER and RE systems.
Our Playbook: Prompting, Extracting, and Scoring with Morphik
Simply throwing raw text at these powerful LLMs and hoping for the best isn’t a strategy. We needed precision and consistency. Here’s how Morphik helped us structure the experiment:- Data Wrangling Made Easy: We took the SciER records, cleverly grouped sentences by document (abstract), and ingested them smoothly into Morphik. Crucially, we stored the human-annotated “ground truth” entities and relations alongside the text as metadata – essential for evaluation later. (Illustrative code snippet below shows the logic)
- Consistent Prompting is Key: We engineered a detailed prompt, guiding the LLMs on exactly what entities (Dataset, Method, Task) and relationships (Used-For, Compare, Evaluate-On, etc.) to extract, and crucially, how to format the output as JSON. Morphik allowed us to define this prompt once, complete with few-shot examples (
EntityExtractionExample), and apply it identically to GPT-4o, Gemini 2 Flash, and Llama 3.2 (GraphPromptOverrides). This consistency is vital for a fair comparison. (Illustrative prompt setup below)
- Orchestrated Extraction: For every abstract and each LLM, Morphik handled the behind-the-scenes dance: sending the text chunk (we used a 600-token chunk size with 300-token overlap – parameters ripe for future tuning!), applying the consistent prompt, calling the correct model API, retrieving the response, and parsing the LLM’s JSON output into a structured graph format using
db.create_graph. This streamlined the generation of comparable knowledge graph snippets from each model.
- Smarter Evaluation (Semantic Similarity): Exact text matching is too brittle for this task. Does “Convolutional Neural Network” not match “CNN”? To get a more realistic score, we implemented semantic similarity using OpenAI’s fast
text-embedding-3-smallmodel. We compared the meaning of extracted entities and relations against the ground truth, considering a match if the cosine similarity score was 0.80 or higher. This acknowledges variations in wording while focusing on conceptual accuracy. Morphik’s structured output made it straightforward to feed data into our evaluation script.
- Visualizing the Verdict: We calculated standard Precision, Recall, and F1-Score for both entity and relation extraction. Morphik’s structured data allowed us to easily generate comparison charts.
The Results: Ding, Ding, Ding!
Alright, the moment of truth. How did our contenders fare in this scientific knowledge extraction showdown, orchestrated via Morphik? (Results Section 1: F1 Score - The Overall Performance) The F1 score balances precision (accuracy of extracted items) and recall (completeness of extracted items). Higher is better.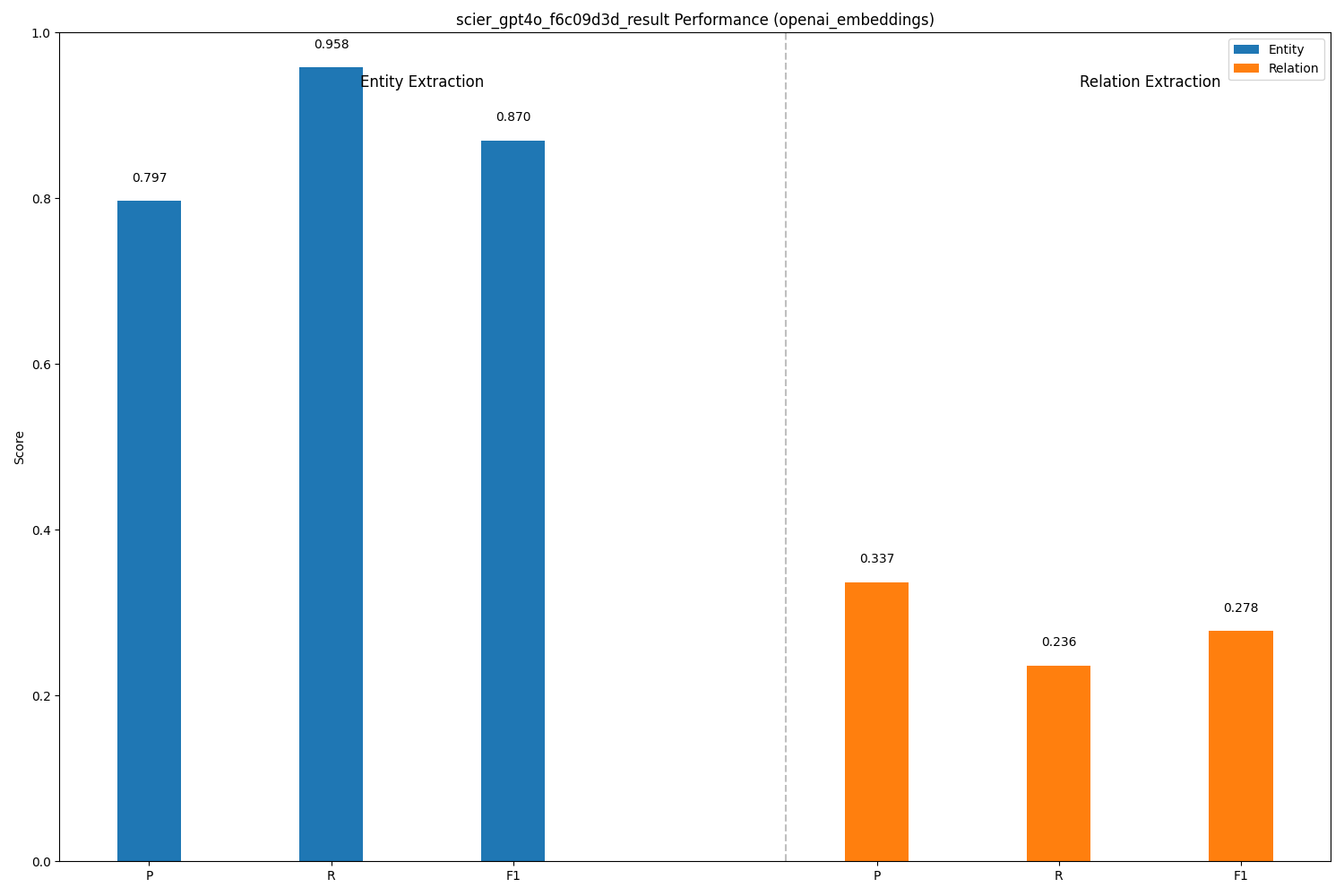
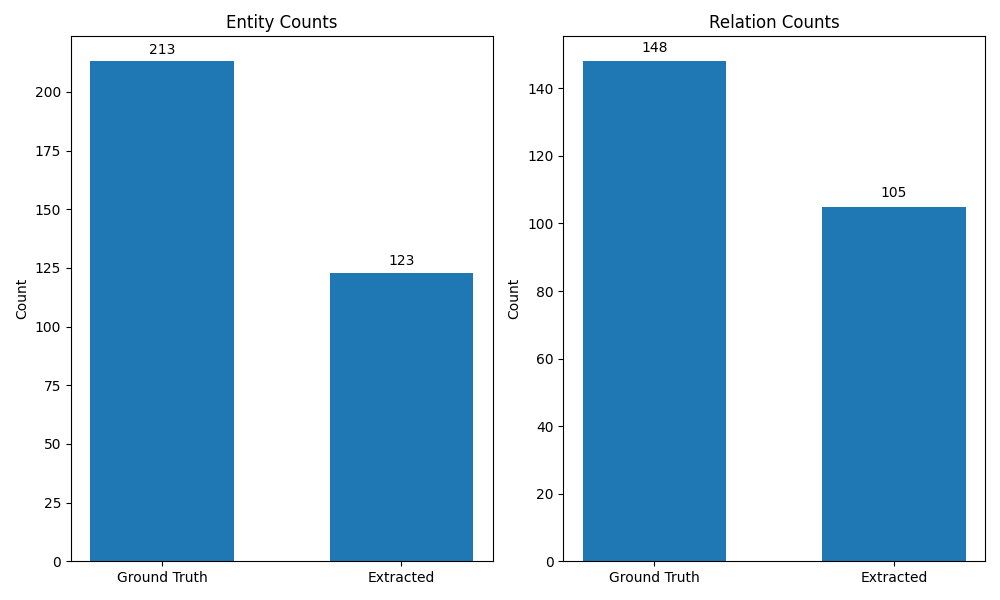
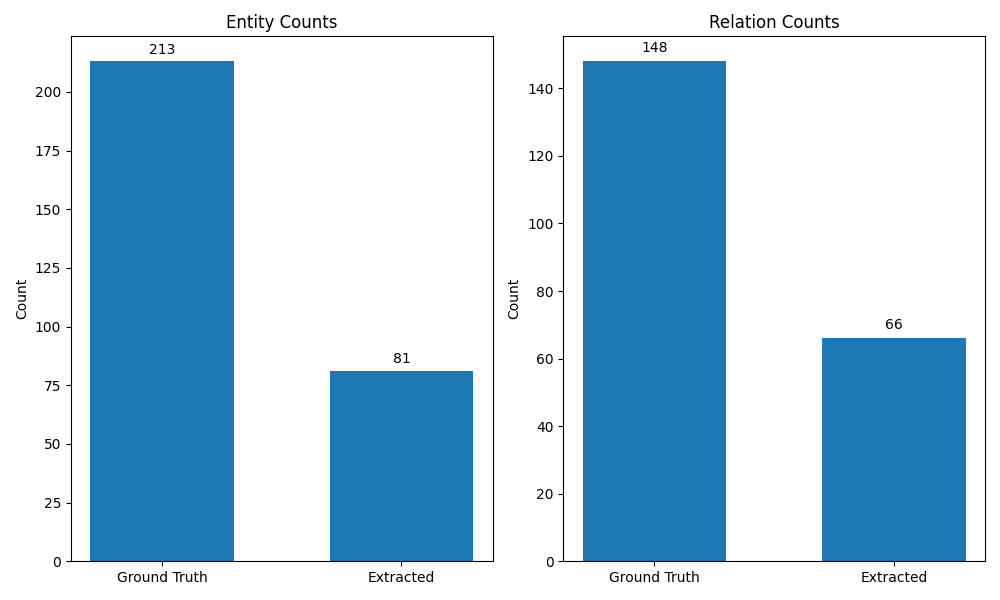
| Model | Task | Precision | Recall | F1 Score |
|---|---|---|---|---|
| GPT-4o | Entity Extraction | 0.797 | 0.958 | 0.870 |
| GPT-4o | Relation Extraction | 0.337 | 0.236 | 0.278 |
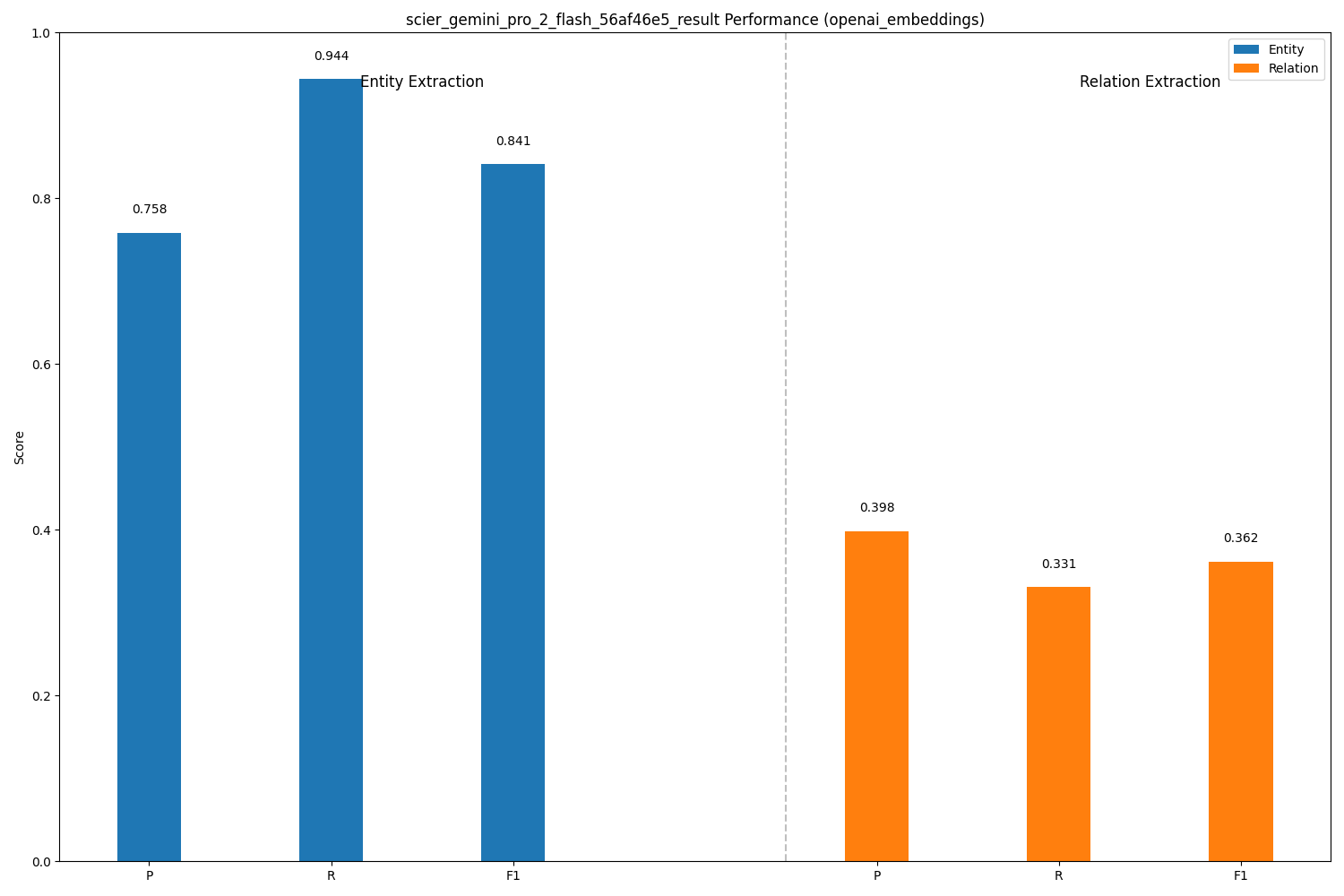
| Gemini 2 Flash | Entity Extraction | 0.758 | 0.944 | 0.841 |
| Gemini 2 Flash | Relation Extraction | 0.398 | 0.331 | 0.362 |
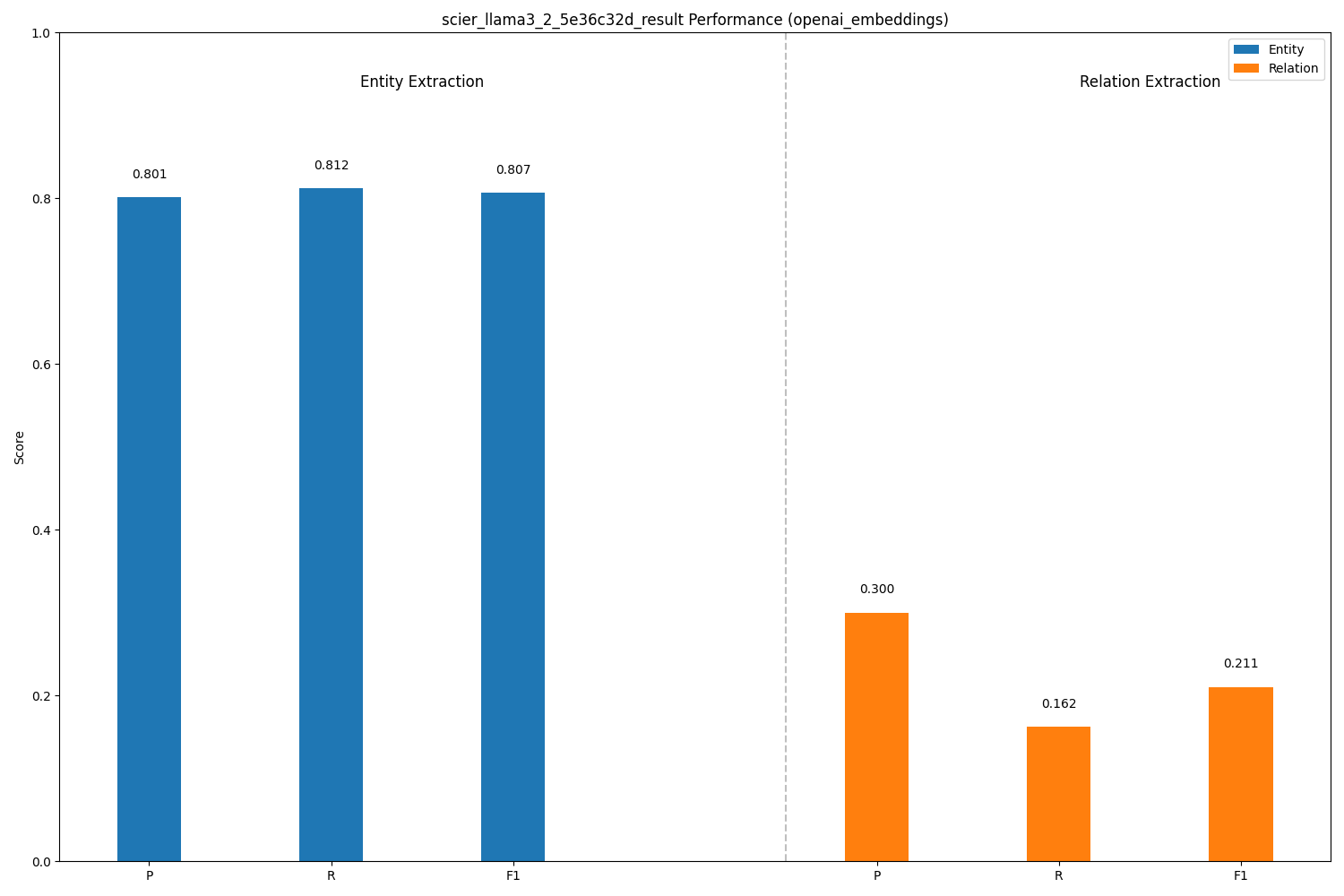
| Llama 3.2 (3B) | Entity Extraction | 0.801 | 0.812 | 0.807 |
| Llama 3.2 (3B) | Relation Extraction | 0.300 | 0.162 | 0.211 |
Unpacking the Results: Insights and Caveats
Morphik’s framework made it easy to compare apples-to-apples. Here’s what stood out:- Entities Easier Than Relations (Big Surprise!): All models found identifying entities (NER) significantly easier than figuring out their relationships (RE). F1 scores dropped drastically (around 50-70%) for RE across the board. This isn’t shocking – understanding the nuanced connections between terms is inherently harder than just spotting the terms themselves.
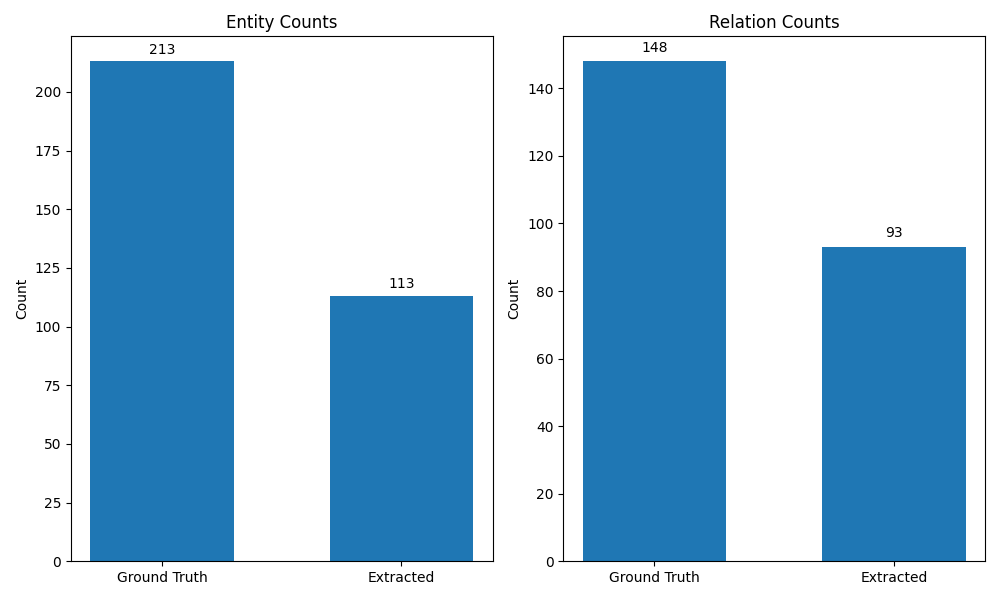
- GPT-4o: The Recall Champion (NER): GPT-4o excelled at finding most of the entities, boasting the highest recall (95.8%) and the top NER F1 score (0.870). However, its higher extracted entity count suggests it might sometimes be slightly over-eager.
- Gemini 2 Flash: The Relation Whisperer? The surprise standout was Gemini 2 Flash in Relation Extraction. It achieved the best RE F1 score (0.362) and the highest RE precision (0.398), suggesting it was more accurate (though still far from perfect) in identifying valid relationships compared to the others in this specific setup.
- Llama 3.2 (3B): Solid Open-Source Contender: Llama 3.2 (3B) delivered respectable NER performance, showing a good balance between precision and recall (and extracting a number of entities very close to the ground truth). Its RE performance lagged, but it remains a strong open-weight option.
- The Claude Conundrum: We initially wanted to include Anthropic’s Claude in this comparison. However, we encountered difficulties getting Claude to consistently adhere to the strict JSON output format required for our automated evaluation pipeline, especially for the complex relationship structures. This wasn’t necessarily a reflection on Claude’s reasoning ability, but it highlighted a practical challenge: for automated KG building workflows like those Morphik enables, reliable, structured output from the LLM is non-negotiable.
- Room for Improvement (Prompts, Chunking): These results reflect our specific experimental setup. We used one detailed prompt and a specific text chunking strategy (600 tokens, 300 overlap). More sophisticated prompt engineering (e.g., chain-of-thought, different examples) or experimenting with chunk sizes could potentially boost performance for all models. This is an iterative game!
Conclusion: LLMs Need Orchestration to Truly Shine in Science
So, can LLMs conquer scientific literature? Our experiment suggests they are becoming incredibly powerful tools for assisting in this conquest, but they’re not quite autonomous conquerors… yet. Key Takeaways:- NER is Getting Good: State-of-the-art LLMs are becoming adept at identifying key entities in scientific text.
- RE is the Next Frontier: Accurately extracting the complex web of relationships remains a major challenge, though models like Gemini 2 Flash show encouraging progress.
- Model Choice Matters: Different LLMs exhibit different strengths. GPT-4o excels at broad identification, while Gemini 2 Flash showed an edge here in relational understanding. Llama 3.2 (3B) offers a strong open alternative.
- Ingest and Prepare diverse data sources.
- Manage and Apply complex, consistent prompts across different models.
- Orchestrate API calls and handle model-specific quirks.
- Structure the often unpredictable LLM outputs into usable formats (like graphs!).
- Integrate smoothly with sophisticated evaluation techniques (like semantic similarity).