At Morphik, we build RAG tools to provide developers accurate search over complex documents. In this article, we explain why we operate over "images" of pages instead of doing OCR/ parsing.
If you’ve ever tried to extract information from a complex PDF: one with charts, diagrams, and tables mixed with text, you know the pain. That invoice with a nested table showing quarterly breakdowns? The research paper whose intricate figures actually contain the key findings? The technical manual where the annotated diagrams explain more than the text ever could? Or maybe the IKEA manual with no text at all.
We’ve all been there, watching our carefully crafted parsing pipeline mangle yet another document. The industry’s dirty secret is that we’re spending enormous effort (and money) on OCR, layout detection, and parsing pipelines that still lose the information that matters most. It’s like trying to “watch” a movie by reading its script: you miss all the visual storytelling that makes it meaningful.
For example, let’s take a very simple all text page (not scanned, no diagrams, etc.) like the one below:

Fig 1: Simple page showing Palantir financials
If I try to parse it with common OCR tools (the values might come out correct, but the headings and values all get jumbled up, add on standard chunking, we might not send correct information when retrieving)
Q1
Financials
US commercial continues to accelerate in Q1 2025 alongside AIP revolution
+71% Y/Y
+65% Y/Y
US Commercial Revenue
US Commercial Customer Count
+19% Q/Q
+13% Q/Q
US Commercial Revenue
US Commercial Customer Count
+127% Y/Y
$810M
US Commercial Remaining Deal Value
2x Y/Y
US Commercial Total Contract Value
+30% Q/Q
US Commercial Deals Closed of $1M or Greater
+183% Y/Y
US Commercial Remaining Deal Value
US Commercial Total Contract Value
2025 Palantir Technologies Inc.
We dene a customer as an organization from which we have recognized revenue during the trailing twelve months period.
This is possibly one of the simplest documents, we haven’t even come to complex or technical documents.
Note/ Aside: You might still need to convert a document to text or a structured format, that’s essential for syncing information into structured databases or data lakes. In those cases, OCR works (with its quirks), but in my experience passing the original document to an LLM is better (we do this with Morphik workflows, learn more here).
The Traditional Approach: A House of Cards
When we started building RAG at Morphik, we did what everyone does: assembled the standard document processing pipeline. You know the one, it starts with OCR and ends with tears.
Here's what that "state-of-the-art" pipeline actually looks like:
- Run OCR on your PDFs (hope it reads the numbers correctly)
- Deploy layout detection models (hope they identify table boundaries)
- Reconstruct reading order (hope it follows the visual flow)
- Caption figures with specialized models (hope they capture the nuance)
- Chunk text "intelligently" (hope you don't split related info)
- Generate embeddings with BGE-M3 or similar (hope meaning survives)
- Store in your vector database (hope you can find it later)
Take a simple invoice with a table showing itemized costs. First, your OCR might read "1,000" as "l,0O0" (those are letters, not numbers). Then your layout detector might miss that the subtotal row is actually part of the table. Your chunking strategy splits the table from its header. By the time you're searching for "total costs for Q3," you're searching through mangled text that bears little resemblance to the original document.
We once spent six hours debugging why our system couldn't find information that was clearly visible in a financial report. Turns out, the parsing pipeline had interpreted a pie chart's legend as body text, scattering percentages throughout unrelated paragraphs.
Even if OCR captured every character flawlessly, the meaning locked inside images, figures, and tables would still vanish. Suppose layout detection nailed every bounding box; you would still rely on figure captioning, and captions inevitably miss critical context. A hybrid approach-feeding text to a text-embedding model and images to an image-embedding model-sounds appealing, yet it shatters the document’s positional context. Queries that depend on spatial relationships (“which part of the diagram labels Q3 total?”) become impossible, embeddings for text and images live in separate spaces, and retrieval pipelines struggle to reconcile them. Positional loss, modality gaps, and fractured semantics compound into answers that feel random. In practice, you still cannot trust the pipeline.
The Lightbulb Moment: What If We Just... Looked at the Page?

The revelation came during yet another debugging session. Arnav, my co-founder (and brother 🙂) asked the question that changed everything: "Why are we deconstructing these documents just to reconstruct meaning? What if we treated them the way humans do: as visual objects?"
It sounds almost too simple. But that's exactly what the recent ColPali research proved possible. Vision Language Models have quietly gotten good enough to understand documents directly. No parsing. No OCR. No reconstruction. Just: Document → Image → Understanding.
The elegance is stunning. Instead of seven fragile steps, you have one robust operation. Instead of losing information at every stage, you preserve everything: every chart, every table relationship, every visual cue that makes documents understandable to humans.
In Fig 1., what the LLM would “see” in this case is direct page itself, maintaining all positional information!
Under the Hood: How Visual Document Retrieval Actually Works
Here's where it gets technically interesting. The ColPali model doesn't just "look" at documents. It understands them in a fundamentally different way than traditional approaches.
The process is beautifully straightforward:
First, we treat each document page as an image, essentially taking a high-resolution screenshot. This image gets divided into patches, like laying a grid over the page. Each patch might contain a few words, part of a chart, or a table cell.
A Vision Transformer (specifically SigLIP-So400m) processes these patches, but here's the clever part: instead of trying to extract text, it creates rich embeddings that understand both textual and visual elements in context. These embeddings are then refined by a language model (PaliGemma-3B) that's been trained to understand document structure.
When you search for "Q3 revenue trends," the magic happens through what's called "late interaction." The model doesn't just look for those exact words, it finds patches containing the text "Q3," the word "revenue," but also the relevant parts of charts showing upward trends, table cells with quarterly figures, and even color-coded elements that indicate performance.
It's like having a human expert who can instantly scan every page and understand not just what's written, but what's shown.
An interesting overview of ColPali by Arnav here. (more to scratch the technical itch)
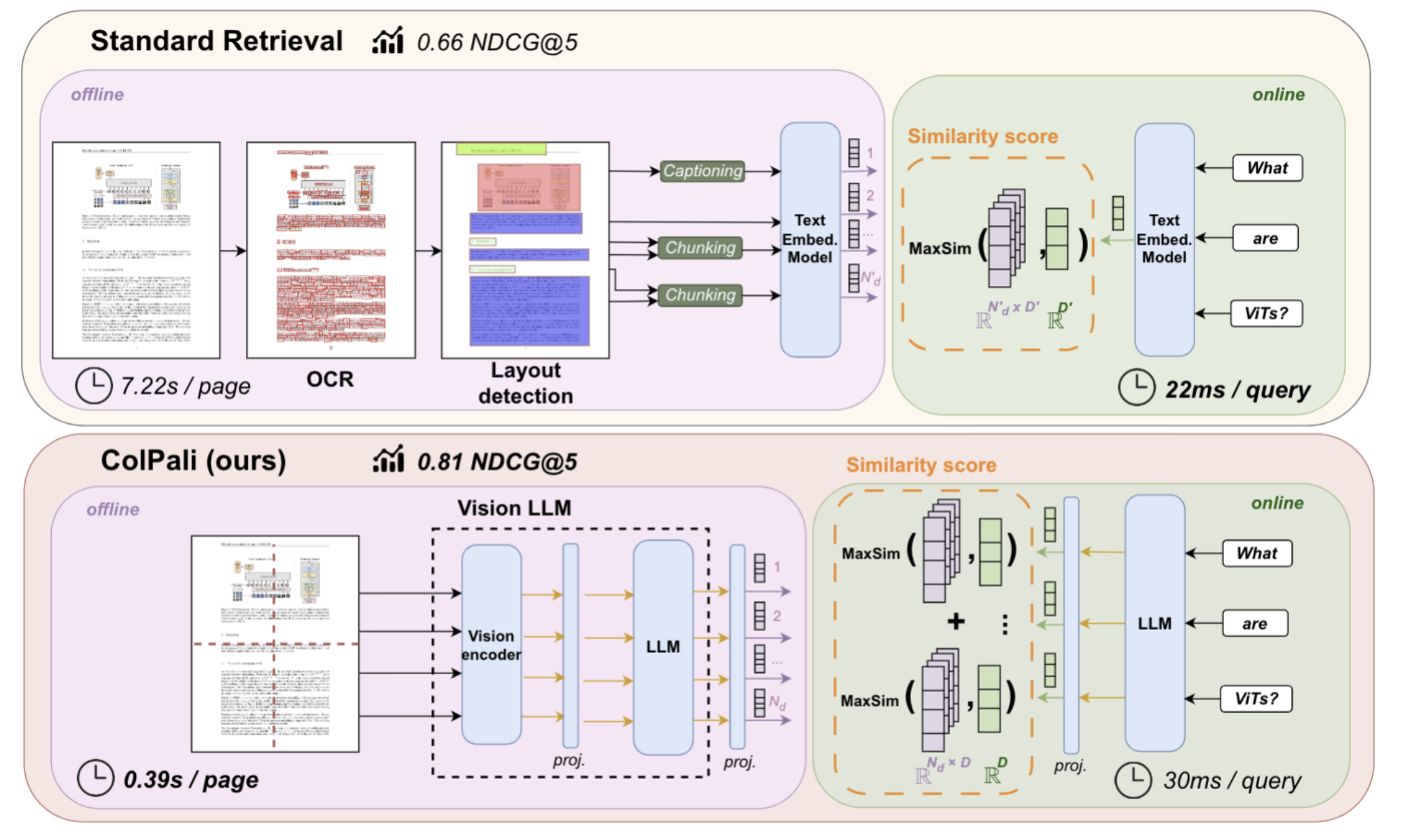
Fig 3: Comparison of traditional pipelines vs ColPali
Real-World Showdown: Morphik vs. The Alternatives
When we built Morphik, we implemented ColPali and quickly discovered that productizing it was far more complex than the research suggested. No vector database directly supported our desired similarity function at that time, and every provider offered optimizations for single vectors instead of multi-vectors, which was painfully slow. We added optimizations like binary quantization and then using Hamming distance for calculation instead of dot product, among other performance improvements... each piece had hidden complexity.
But the real test came when we compared our approach to existing solutions.
Systematic Evaluation: The Numbers Don't Lie
To validate these observations beyond anecdotal evidence, we worked with TLDC (The LLM Data Company) to build an open-source financial document benchmark with 45 challenging questions across NVIDIA 10-Qs, Palantir investor presentations, and JPMorgan reports. TLDC has a complex multistep process for generating these evaluations, and their objective was frankly to humiliate us. They wanted questions that would expose the limitations of any document retrieval system. The evaluation harness is designed to be easy to use, and anyone can test their RAG system against these same questions and see how they stack up.
The results were striking: while other end-to-end providers peaked at around 67% accuracy, and even a carefully optimized custom LangChain pipeline with semantic chunking and OpenAI's text-embedding-large model achieved 72%, Morphik delivered 95.56% accuracy on the same evaluation set. For comparison, OpenAI's file search tools, which represents a solid baseline, managed only 13.33% accuracy on these challenging financial document questions.
On the ViDoRe benchmark, the first evaluation specifically designed for visual document retrieval, our approach achieves 81.3% nDCG@5 compared to 67.0% for traditional parsing methods. But as our own evaluation shows, benchmarks only tell part of the story. The real difference is in understanding documents the way they were meant to be understood.
Want to test your own system? The entire evaluation framework is ready to use. Just clone the repo, add your RAG implementation, and see how it performs on the same challenging financial document questions.
The Speed Problem (And How We Solved It)
Ok so we got to really good accuracy, but 'll be honest: our first implementation was slow. Visual understanding is computationally intensive, and ColPali's original multi-vector approach meant searching through millions of patch embeddings at scale. At 3-4 seconds per query for retrieval, it was impressive but not production-ready for our customers querying thousands of documents and demanding something fast.
The breakthrough came from the MUVERA paper. Instead of searching through all patch embeddings independently, MUVERA reduces multi-vector search to single-vector similarity using fixed-dimensional encodings. Think of it as creating a "summary fingerprint" that preserves the rich patch interactions while being orders of magnitude faster to search.
We paired this with Turbopuffer, a vector database built for exactly this use case. The results transformed our system, and our query latency went from 3-4s to 30ms.
The math works out beautifully: we can now search millions of documents faster than traditional systems can parse a single PDF.
What This Means for You
Forget wrestling with document parsing libraries. Forget maintaining separate pipelines for text extraction, table detection, and OCR. Forget losing critical information every time a document doesn't fit your parsing assumptions.
With visual document retrieval, you just send us your documents—PDFs, images, even photos of whiteboards—and search with natural language. It works particularly well for:
- Financial documents: Where charts and tables tell the real story
- Technical manuals: Where diagrams are worth thousands of words
- Invoices and receipts: Where layout and structure carry meaning
- Research papers: Where figures contain the actual findings
- Medical records: Where visual layouts indicate relationships
The API is deliberately simple: upload your documents, search with queries like "show me all contracts with penalty clauses over $10K" or "find the deployment architecture diagram from last year's proposal."
The Future: Beyond Simple Retrieval
Visual document understanding solves the foundational problem, but real-world document workflows demand much more than single-shot retrieval. The future we're building toward involves documents that truly understand context, relationships, and complex reasoning chains.
Multi-Document Intelligence: Today's systems treat each document as an island. Tomorrow's will understand how your Q3 financial report relates to the board deck from last month, how contract amendments reference the original agreement, and how technical specifications connect to implementation guides. At Morphik, we're already building multi-document retrieval that can trace information across entire document ecosystems, jumping seamlessly from page to page, document to document, following the logical threads that human experts would pursue.
Agentic Document Reasoning: Simple Q&A is just the beginning. We're developing agentic systems that can perform multi-hop reasoning across documents—finding a contract clause, checking it against regulatory requirements in another document, then cross-referencing implementation details in a technical manual. Our knowledge graph capabilities help these agents understand not just what's in documents, but how different pieces of information relate to each other.
Workflow Integration: The most powerful applications emerge when document understanding becomes part of broader business processes. Imagine systems that automatically flag contract discrepancies by comparing terms across multiple agreements, or that can trace a technical decision from initial requirements through design documents to implementation guides. We're building tools that don't just retrieve information—they understand it well enough to take action.
The Gap We're Still Bridging: Despite these advances, we're honest about the limitations. Current systems, including ours, still fall short of true expert-level understanding. A human financial analyst doesn't just find numbers in a report—they understand market context, recognize subtle implications, and spot inconsistencies that require years of domain expertise. While our visual approach captures information that traditional parsing misses, we're still working toward systems that can provide the kind of ironclad guarantees that mission-critical decisions require.
What's Next: The path forward involves deeper integration between visual understanding and domain knowledge. We're exploring how to combine our visual document retrieval with specialized knowledge graphs, how to build systems that can reason about causality and implication rather than just correlation, and how to provide the kind of confidence intervals and uncertainty quantification that enterprise applications demand.
This isn't just about technology; it's about respecting how humans create and consume information. Documents are visual artifacts embedded in complex workflows, and they deserve to be understood not just as isolated objects, but as part of the rich, interconnected systems of knowledge that drive real decisions.
Want to see how these capabilities can transform your document workflows? Try Morphik free at morphik.ai and join us in building a world where documents are understood, not dissected.