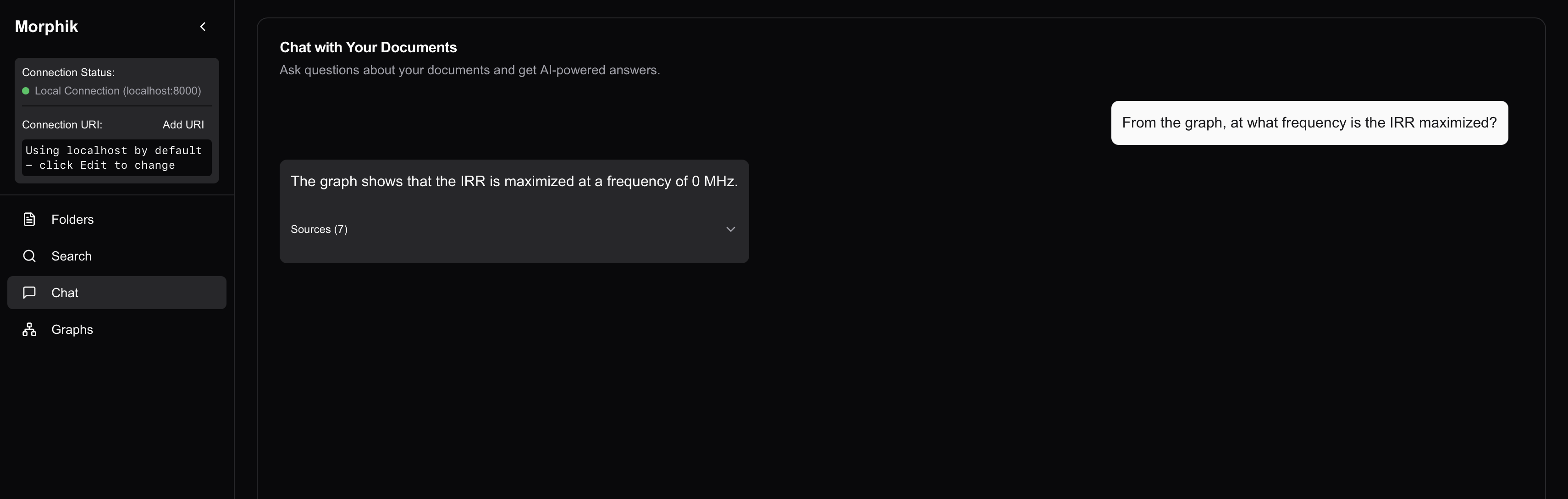
Here's the sequence for o4-mini-high:
You hand o4‑mini‑high a technical patent with an embedded IRR vs Frequency graph and ask:
"At what frequency does IRR peak?"
It thinks for 30 seconds and instead of just reading the chart, it hits you with:
"Which page is that on?"
Cue dramatic facepalm. 🤦
Even after I grumbled "Page 6," it pulled out the Python tool use gun (my favorite as well) proclaimed the peak was "the highest point on the line." Technically wrong and hilariously sure of itself.
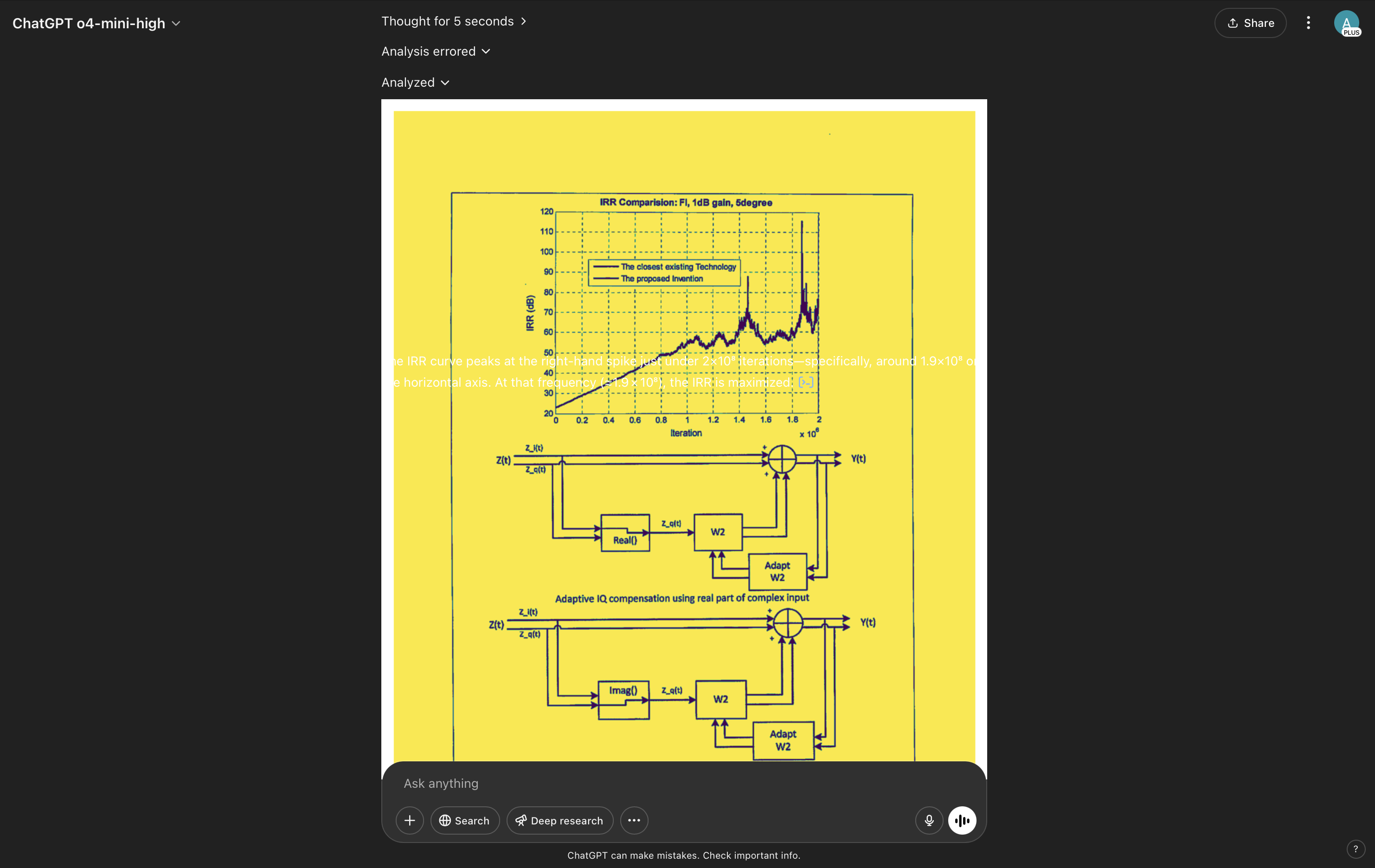
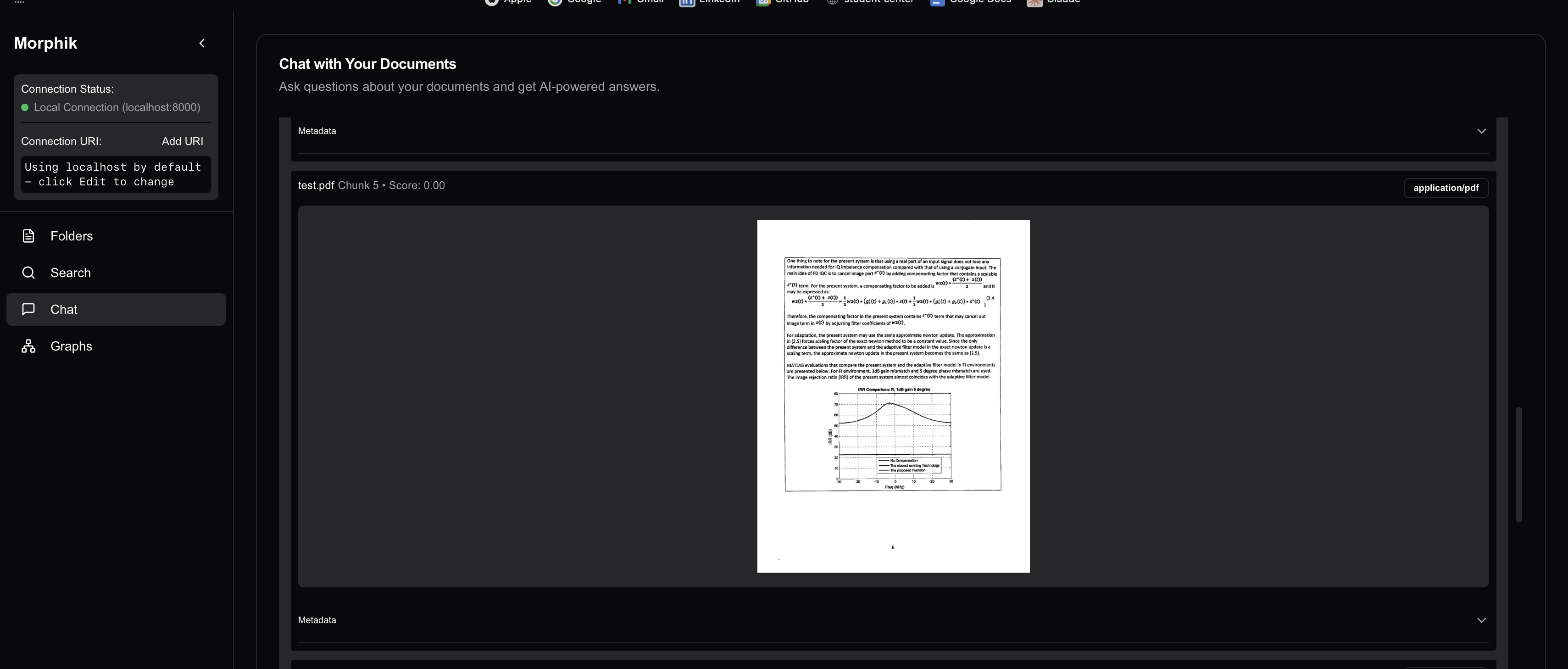
Here's the sequence for Morphik:
We treat each page like one giant image+text puzzle:
- Snap the whole page as an image (diagrams, tables, doodles included)
- Extract text blocks with their exact positions (headings, captions, footnotes)
- Blend vision & text embeddings into a multi-vector cocktail 🍹
- Retrieve the full region (text+diagram) as a unit—no more orphaned charts
Result? The same question returns:
"IRR peaks at 0 MHz." Boom. 🎯